Oh man. I used PostScript a ton when I worked at hp 20 years ago. It's actually a pretty great language, like lisp/scheme but I found it to be more approachable somehow. Maybe because it's postfix instead of prefix?
Anyway, it had several fatal flaws. I don't think it could handle images natively, so instead it encoded them as vectors and those files took up MB. It probably just needed a metaphor like iframe.
I remember when Apple switched to the PDF engine in Quartz in preparation for OS X in the late 90s, I thought it was a mistake then. The QuickDraw it was replacing was actually quite good, in some ways the epitome of C-style rendering. And Cocoa was refreshing at first (it handled stuff like palettes and gamma in a data-driven way instead of through leaky abstractions) but without a way to transition off QuickDraw, it felt like more busywork that had to be done just to keep up.
Apple seems to have lost its academic roots, and suffers for it now. Or I should say, its customers suffer while it grosses almost half a trillion dollars per year. At least with vibe coding we can just whip up a Preview app in an afternoon, so maybe none of this matters anymore.
> Apple seems to have lost its academic roots, and suffers for it now. Or I should say, its customers suffer while it grosses almost half a trillion dollars per year. At least with vibe coding we can just whip up a Preview app in an afternoon, so maybe none of this matters anymore.
Eh, I'm with Apple on this one: we can just use Ghostscript. Apple's move effectively forces the few applications that need to use PostScript on macOS to migrate from a proprietary PostScript implementation to an OSS one, which strikes me as ultimately a good thing.
Yes, PostScript is a great general purpose high level programming language, kind of like a cross between Forth and Lisp, but a lot more like Lisp, with its polymorphic homoiconic data structures that were essentially JSON.
>PostScript is kind of like a cross between Forth and Lisp, but a lot more like Lisp actually. And its data structures, which also represent its code, are essentially s-expressions or JSON (polymorphic dicts, arrays, numbers, booleans, nulls, strings, names (interned strings), operators (internal primitives), etc.)
>Kragen is right that PostScript is a lot more like Lisp or Smalltalk than Forth, especially when you use Owen Densmore's object oriented PostScript programming system (which NeWS was based on). PostScript is semantically very different and much higher level that Forth, and syntactically similar to Forth but uses totally different names (exch instead of swap, pop instead of drop, etc).
>You're welcome! OOPS (Object Oriented PostScript ;), I meant to say that PostScript and Lisp are homoiconic, but Forth is not. The PSIBER paper on medium goes into that (but doesn't mention the word homoiconic, just describes how PS data structures are PS code, so a data editor is a code editor too).
The Shape of PSIBER Space: PostScript Interactive Bug Eradication Routines — October 1989:
>PostScript is often compared to Forth, but what it lacks in relation
to Forth is a user-extensible compiler. You can write your own
PostScript control structures and whatnot, like case and cond, to
which you pass procedures as arguments on the stack, but the
PostScript scanner is not smart -- but there is no preprocessing done
to the PostScript text being read in, like the way immediate words in
Forth can take control and manipulate the contents of the dictionary
and stack while the text source is being read in and compiled, or like
the way Lisp macros work. This is one of the things I would like to
be able to do with something like LispScript.
>"Lisp is the language for people who want everything, and are willing to pay for it." -Russell Brand (the old school Lisp hacker "wuthel" from MIT, not the crazy MAGA rapist)
If you want to efficiently implement a PostScript interpreter with rendering in the web browser (or node), you just have to reach for the canvas 2d rendering context, which is essentially the full PostScript stencil/paint imaging model upgraded to the Porter/Duff compositing model with alpha channels, but without the user defined font rendering and halftoning machinery (which you could implement on top of it).
PostScript has always had the black and white "image" and "imagemask" operators, but they are clumsy, don't support any kind of image processing, and you have to use "readhexstring" to read hex images, but later versions support color images.
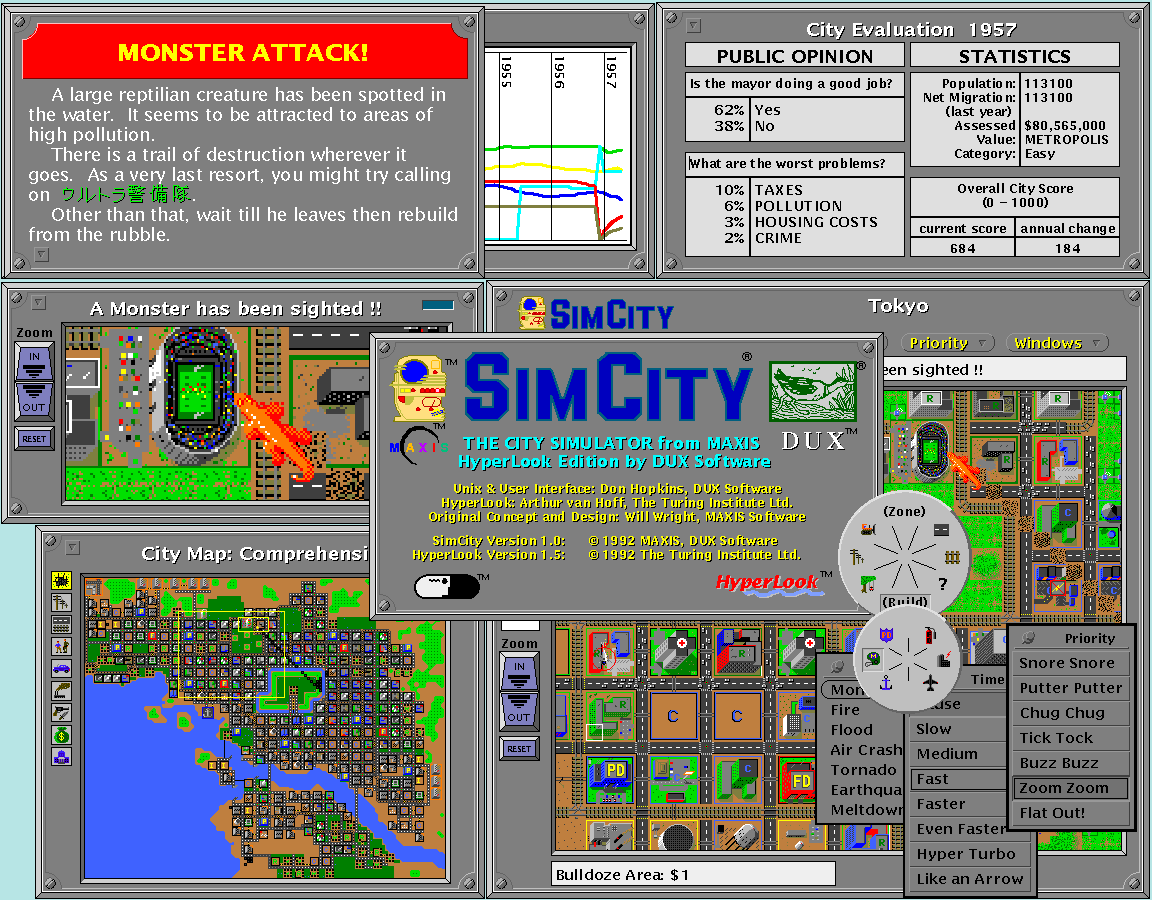
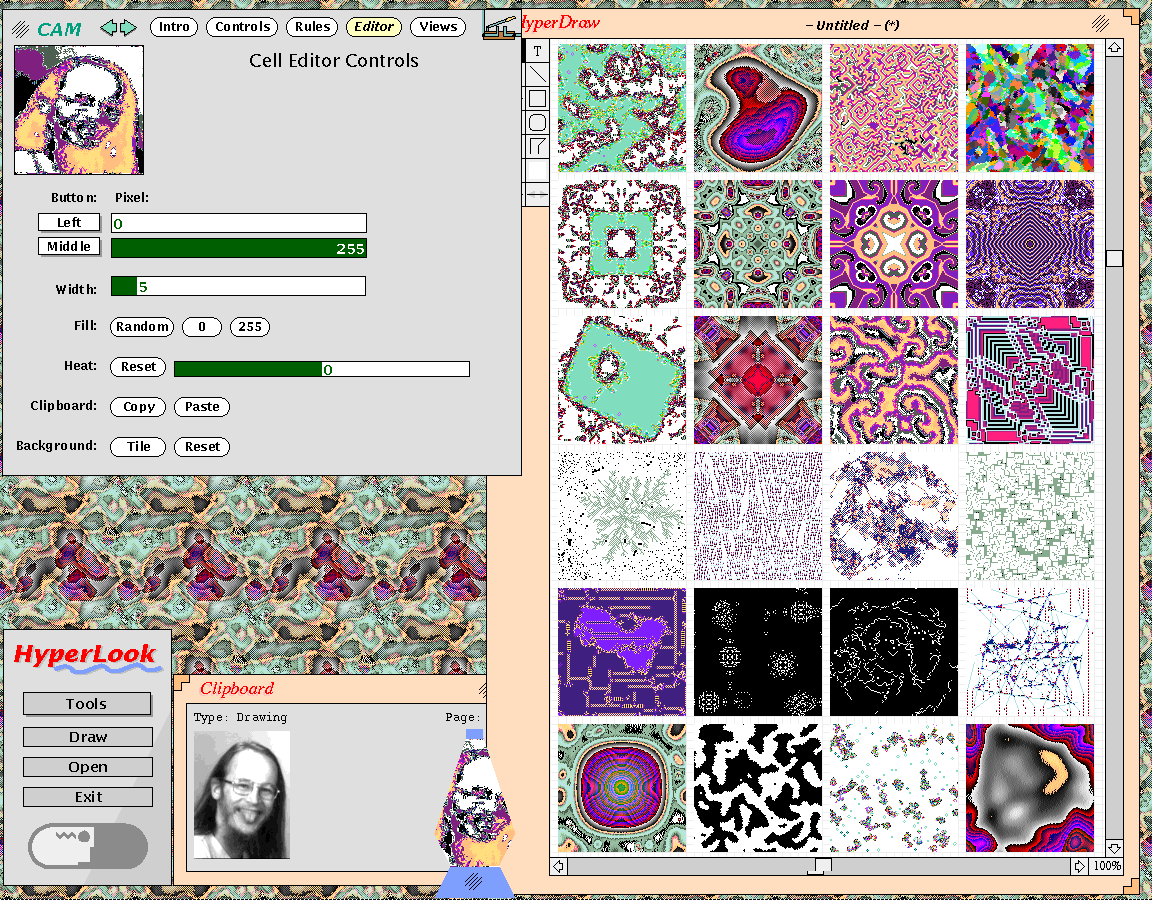
NeWS has "readcanvas" to directly read binary Sun raster files (including color) from files and over the network. It also had memory mapped canvases, which I used for the HyperLook version of SimCity so the C simulator engine could efficiently render the tiles and map views with overlays into memory, and NeWS could scale and render them quickly. I also used memory mapped canvases for my NeWS/HyperLook cellular automata machine, which was implemented in C and scaled and rendered and had a real time painting UI implemented in NeWS PostScript (the client and server took turns "owning" the pixels by ping-ponging messages over the localhost network, so each could draw into the cells in turn, and you could render PostScript directly into the 8-bit color cells for interesting effects, melt people's faces, and clip them on the screen to a window in the shape of a lava lamp).
The Apple PostScript printer drivers used (and Adobe's Blue Book documented) an indirect but efficient hack that tricked the custom halftone rendering machinery into performing a perfect pattern fill (so you could print MacDraw files, etc).
DonHopkins on March 13, 2020 | parent | context | favorite | on: Finding Mona Lisa in the Game of Life
Error diffusion dithering would work very well as initial conditions for many cellular automata rules like Life, especially counting rules (which life is) that stay alive with intermediate numbers of neighbors.
Conway's Life stays alive with 2 or 3 neighbors out of 9, or 2/9 .. 3/9, so gray scales between 22% .. 33% would be the most active.
Halftone screens would have different results, but their regularity might work well with certain CA rules and screens.
PostScript gives you a lot of control over the halftone screen definition.
Halftone screens can use any kind of repeating pattern, there just has to be the proper ratio of white to black pixels to make it look the right brightness. You could even design a set of halftone screen patterns that were precisely matched with a particular cellular automata rule to produce interesting fertile or static patterns. And you can even use any arbitrary pattern for each level, even if they aren't the right brightness, for aesthetic reasons.
The original PostScript LaserWriter was able to efficiently perform pattern fills to print tiled MacDraw images, by defining a custom halftone screen for each tile pixel pattern, that printed precisely the right pixels when you set just the right gray level: the ratio of on pixels to the total number of pixels in the tile. The spot function basically tells the halftone screen machinery what order to turn the dots on as the gray level goes from 1 to 0 (which results is seamless tiling with nearby gray tiles). Take a look at the PostScript header of an old MacDraw file some time to see the really bizarre code that does that by abusing the "setscreen" operator with a contrived spot function. (That was extremely tricky and gave GhostScript problems for years. The trick is documented in Program 15 page 193 of the awesome PostScript "Blue Book", and it uses a lot of memory! It's one of the coolest tricky PostScript hacks I've ever seen!)
>This program demonstrates how to fill an area with a bitmap pattern using the POSTSCRIPT halftone screen machinery. The setscreen operator is intended for halftones and a reasonable default screen is provided by each POSTSCRIPT implementation. It can also be used for repeating patterns but the device dependent nature of the setscreen operator can produce different results on different printers. As a solution to this problem the procedure, ‘‘setuserscreen,’’ is defined to provide a device independent interface to the device dependent setscreen operator.
>IMPLEMENTATION NOTE: Creating low frequency screens (below 60 lines per inch in device space) may require a great deal of memory. On printing devices with limited memory, a limitcheck error occurs when storage is exceeded. To avoid this error, it is best to minimize memory use by specifying a repeating pattern that is a multiple of 16 bits wide (in the device x-direction) and a screen angle of zero
> .. with vibe coding we can just whip up a Preview app
why deflate your own position with this (worthless-untrue-spineless) statement? Which library is doing the work? who writes that library and maintains it?
that was a real product with ordinary thousands of hours of skilled coding in there.. That is certainly the part that is doing work. Secondly someone really knows what they are doing to slip in those architectural layers / shims / pipes .. Very impressive IMHO
It's partially because the internet only grants us free storage (noun), not free compute (verb).
Which is fundamental to so many XY problems, including why cloud services are so byzantine instead of just providing isolated secure shells with full root access within them. And why distrust is a growing force in the world instead of, say, unconditional love.
I always dreamed of winning the internet lottery so that I could help dismantle the systems of control which currently dominate our lives. Which starts with challenging paradigms from first principles. That looks like asking why we only have multicore computing in the cloud and not on our desktops (which could be used to build our own cloud servers).
When we're missing an abstraction layer, that creates injustice and a power drain from the many to the few. Some examples:
- CPU -> multicore MIMD (missing) -> GPU (based on the subset SIMD instead of MIMD upon which graphics libraries could be built)
- UDP -> connectionless reliable stream (missing) -> TCP (should have been a layer above UDB not beside it)
- UDP/TCP -> P2P (NAT and other limitations block this and were inherited by IPv6 as generational trauma) -> WebRTC (redundant if we had P2P that "just works")
- internet connection -> symmetric upload/download speed (blocked for legal reasons under the guise of overselling to reduce cost) -> self-hosted web servers (rare due to antitrust issues stemming from said legal reasons)
- internet connection -> multicast (missing due to suppression of content-addressable-memory/hash-tree/DHT/) -> self-hosted streaming (negates the need for regions and edge caching)
I had high hopes for Google and even Tesla (for disrupting the physical world). But instead of open standards, they gave us proprietary vendor lock-in: Google Workspace (formerly G Suite) and NACS instead of J1772 (better yet both). Because of their refusal to interoperate at the lowest levels, there is little hope that they will do the real work of solving the hard problems at the highest levels.
For example, I just heard that China has built thousands of battery swap stations to provide effectively instant charging for electric vehicles, whereas that's something that Tesla can't accomplish because they chose to build Supercharger stations instead.
Once we begin to see the world this way, it's impossible to unsee it. It calls into question the fundamentals (like scarcity) which capitalism is based upon, and even the concept of profit itself.
From a spiritual perspective, I believe that this understanding is what blocks me from using my talents to use the system for personal gain to win the internet lottery. The people who own the systems of control don't have this understanding, and even view its basis in empathy as a liability. So we sacrifice the good of the many for the good of the few and call that progress.
In his 1999 book "Entering Space: Creating a Spacefaring Civilization", Robert Zubrin mentioned checking the math for Bussard ramjets with Dana Andrews in their 1988 join paper "Magnetic Sails and Interstellar Travel" and found that they aren't capable of reaching more than a few percent of the speed of light before drag overcomes propulsion:
That's not to say that they don't work. But they'll probably be used primarily for braking to enter orbit around destination stars.
Probably the only way to reach a high fraction of the speed of light is to construct a giant laser to beam energy to a spaceship (which uses a reflector to receive light pressure momentum) and leave it behind orbiting the origin star. That's the premise of the Breakthrough Starshot project, which is ambitious with today's technology. But with self-replicating makerbots, building one may not be a big deal.
Unfortunately the force of light pressure (by F=2P/c for full reflection) is only about 2/3 of a kg or 1.5 lbs per GW, so a TW or greater would be needed for practical thrust. However, light pressure becomes the most efficient form of propulsion above about 25% to 50% c, if fusion or antimatter is used to create a gamma ray rocket.
Personally, I find it unlikely that aliens use these methods. I think that they probably worked out how to build neutrino lasers, since they don't burn up objects in their wake, perhaps by scaling superradiant Bose Einstein condensates:
In embarrassingly oversimplified layman's terms, I think that works by recruiting the macro-scale quantum state of the condensate (increased cross-section or barn) to overcome the short interaction distance of the weak force. Or by cooling the atoms to such an extent that they don't have the energy to hold themselves apart anymore, which accelerates their decay. I'm sure my explanations are wrong somehow.
Soon we may be able to investigate stuff like gravity waves and how the fabric of spacetime may be able to rebound above flat to create tiny ripples that allow mass energy to escape black holes, for example. I know that current theories don't state it quite that way, but if we consider stuff like the no-hair theorem and black box thought experiments, it's hard to see how Hawking radiation could exist without the wavelike nature of spacetime. We can even experiment with it on a relatively large scale by measuring the Casimir force. If we can rebound space, then we can play with stuff like negative energy and Alcubierre drives.
I looked up a Dyson sphere made from Mercury and it would be 1.5 mm thick, so aliens almost certainly aren't building them. But Dyson rings and swarms are probably a thing.
Some people in the tinfoil hat crowd think that UFOs can move 4th dimensionally and just travel orthogonally to our space and appear somewhere else. Theoretically, that might only require the energy difference (delta v) between planets. That hinges on if gravity spans higher dimensions and also touches on the multiverse. I'm way outside my wheelhouse so I'll stop blabbering about that.
In all honesty though, I question whether aliens travel. I think civilizations ascend about 10 years after they implement AI, or annihilate themselves in a Great Filter, their equivalent of WWIII. We're already staring the secrets of the universe in the face with automated theorem provers. And FUD around that and other accelerating tech drives people to become Luddites and elect amoral people who would gladly see the world burn for profit. So things could go either way really.
In my heart, I feel like we have a childlike understanding of consciousness. It probably transcends 4D spacetime. It's not hard to imagine aliens scaling what was learned from the CIA Gateway Program and doing stuff like FTL message passing via remote viewing. At that point FTL teleportation comes into the realm of possibility, sort of like in Dune.
If so, then aliens are probably everywhere, know about us, and maybe had a hand in our evolution. The probably live in what we think of as a Matrix, where years could go by for every second of our time. Another interpretation might be that they're able to return to source consciousness and exist as one, rather than in separation like we do. Maybe they periodically choose to reincarnate in us to study what transitioning to a spacefaring civilization looks like.
I probably shouldn't have bothered writing all of this, but it's Sunday, and I also really don't want to do my taxes.
Just wanted to mention genetic algorithms (GAs), popularized by John Koza and others.
The post uses a 4 instruction program as an example having about 256^4 or 4 billion combinations. Most interesting programs are 10, 100, 1000+ instructions long, which is too large of a search space to explore by brute force.
So GAs use a number of tricks to investigate the search space via hill climbing without getting stuck at local optima. They do that by treating the search space as a bit string, then randomly flipping bits (mutation) or swapping bits (sexual reproduction) to hop to related hills in the search space. Then the bit string is converted back to instructions and tested to see if it performs the desired algorithm.
The bit string usually encodes the tree form of a Lisp program to minimize syntax. We can think of it as if every token is encoded in bits (like Huffman encoding inspired by Morse code) For example, the tokens in a (+ 1 2) expression might have the encoding 00, 01 and 10, so the bit string would be 000110, and we can quickly explore all 2^3 = 8 permutations (2^6 = 64 if we naively manipulate an uncompressed bit string whose encoded token sizes vary).
Note that many of the bit strings like (+ + 1) or (2 1 +) don't run. So guard rails can be added to reduce the search space, for example by breaking out early when bit strings throw a compiler exception, or using SAT solvers or caching to weed out nonviable bit strings.
We could build a superoptimizer with GAs, then transpile between MOS 6502 assembly and Lisp (or even run the MOS 6502 assembly directly in a sandbox) and not have to know anything about how the processor works. To me, this is the real beauty of GAs, because they allow us to solve problems without training, at the cost of efficiency.
I don't think that LLMs transpile to Lisp when they're designing algorithms. So it's interesting that they can achieve high complexity and high efficiency via training, without even having verification built-in. Although LLMs trained on trillions of parameters running on teraflops GPUs with GBs of memory may or may not be viewed as "efficient".
I suspect that someday GAs may be incorporated into backpropagation to drastically reduce learning time by finding close approximations to the matrix math of gradient descent. GAs were just starting to be used to pseudorandomly produce the initial weights of neural nets around 2000 when I first learned about them.
Also quantum computing (QC) could perform certain matrix math in a fraction of the time, or even preemptively filter out bit strings which aren't runnable. I suspect that AI will get an efficiency boost around 2030 when QC goes mainstream. Which will probably lead us to a final candidate learning algorithm that explains how quantum uncertainty and emergent behavior allow a physical mind to tune into consciousness and feel self-aware, but I digress.
Because modern compilers don't do any of this, and we aren't accustomed to multicore computing, then from a sheer number of transistors perspective, we're only getting a tiny fraction of the computing power that we might otherwise have if we designed chips from scratch using modern techniques. This is why I often say that computers today run thousands of times slower than they should for their transistor budgets.
Andreessen's criticism of introspection, and Musk's criticism of empathy, are projections of their fear of being disconnected from spirit (primarily the notion that we're all one).
Some of us eventually find ourselves in situations that defy logical explanation. I've witnessed my own thoughts and plans rippling out into the world and causing external events to unfold. To the point that now, I'm not sure that someone could present evidence to me to prove that our inner and outer worlds aren't connected. It's almost as hard of a problem as science trying to solve how consciousness works, which is why it has nothing to say about it and leaves it to theologians.
The closest metaphysical explanation I have found is that consciousness exists as a field that transcends 4D timespace, so our thoughts shift our awareness into the physical reality of the multiverse that supports its existence. Where one 4D reality is deterministic without free will, 5D reality is stochastic and may only exist because of free will. And this happens for everyone at all times, so that our individuality can be thought of as drops condensed out of the same ocean of consciousness. One spirit fragmented into countless vantage points to subjectively experience reality in separation so as to not be alone.
Meaning that one soul hoarding wealth likely increases its own suffering in its next life.
That realization is at odds with stuff like western religion and capitalism, so the wealthy reject it to protect their ego. Without knowing that (or denying that) ego death can be a crucial part of the ascension process.
My great frustration with this is the power imbalance.
Most of us spend the entirety of our lives treading water, sacrificing some part of our prosperity for others. We have trouble stepping back from that and accepting the level of risk and/or ruthlessness required to take from others to give to ourselves. We lose financially due to our own altruism, or more accurately the taking advantage of that altruism by people acting amorally.
Meanwhile those people win financially and pull up the ladder behind them. They have countless ways, means and opportunities to reduce suffering for others, but choose not to.
The embrace or rejection of altruism shouldn't be what determines financial security, but that's the reality we find ourselves in. Nobility become its opposite.
That's what concepts like taxing the rich are about. In late-stage capitalism, a small number of financial elites eventually rig the game so that others can't win, or arguably even play.
It's the economic expression of the paradox of tolerance.
So the question is, how much more of this are we willing to tolerate before the elites reach the endgame and see the world burn?
Note that we had the technology to do this affordably as of about 2008, when lithium iron phosphate (LiFePO4) batteries became widely available for about $10-12 each (I had to look that up). They were definitely available at low cost ($6) by 2018:
Looks like sodium-ion (Na-ion) 18650 batteries at 1.5 Ah have about 1/2 the capacity of LiFePO4 18650s at 3.5 Ah, and are about twice the price, so lets call them 4x the price per energy stored:
So we can project that Na-ion batteries will have the same price per kWh as today's LiFePO4 in perhaps 8 years, or around 2034, if not sooner. That will negate the lithium supply chain bottleneck so that we're limited to ordinary shortages (like copper).
500 W bifacial solar panels are available for $100 each in bulk, so there's no need to analyze them since they're no longer the bottleneck. A typical home uses 24 kWh/day, so 15-20 panels at a typical 4.5 kW/m2 solar insolation provide enough power to charge batteries and still have some energy left over, at a cost of $1500-2000. Installation labor, electricians/licensing, inverters and batteries now dominate cost.
The sodium ion battery market is about $1 billion annually, vs $100 billion for lithium ion. It took lithium about 15-20 years to grow that much. So whoever gets in now could see a 1-2 orders of magnitude return over perhaps 8-15 years. I almost can't think of a better investment outside of AI.
-
I've been watching this stuff since the 1980s and I can tell you that every renewable energy breakthrough coincides with a geopolitical instability. For the $8 trillion the US spent on Middle East wars since 9/11, we could have had a moonshot for solar+batteries and be at 90+% coverage today. Not counting the other $12 trillion the US spent on the Cold War. Fully $20 trillion of our ~$40 trillion US national debt went to funding endless war, with the other $20 trillion lost on trickle-down tax cuts for the ultra wealthy.
We can't do anything about that stuff in the short term. But we can move towards off-grid living and a distributed means of production model where AI, 3D printing, permaculture, and other alternative tech negates the need for investment capital.
In the K-shaped economy, the "if you can't beat 'em, join 'em" phrase might more accurately be stated "if you can't join 'em, beat 'em".
Forkrun is part of a vanishingly small number of projects written since the 1990s that get real work done as far as multicore computing goes.
I'm not super-familiar with NUMA, but hopefully its concepts might be applicable to other architectures. I noticed that you mentioned things like atomic add in the readme, so that gives me confidence that you really understand this stuff at a deep level.
My use case might eventually be to write a self-parallelizing programming language where higher-order methods run as isolated processes. Everything would be const by default to make imperative code available in a functional runtime. Then the compiler could turn loops and conditionals into higher-order methods since there are no side effects. Any mutability could be provided by monads enforcing the imperative shell, functional core pattern so that we could track state changes and enumerate all exceptional cases.
Basically we could write JavaScript/C-style code having MATLAB-style matrix operators that runs thousands of times faster than current languages, without the friction/limitations of shaders or the cognitive overhead of OpenCL/CUDA.
-
I feel that pretty much all modern computer architectures are designed incorrectly, which I've ranted about countless times on HN. The issue is that real workloads mostly wait for memory, since the CPU can run hundreds of times faster than load/store, especially for cache and branch prediction misses. So fabs invested billions of dollars into cache and branch prediction (that was the incorrect part).
They should have invested in multicore with local memories acting together as a content-addressable memory. Then fork with copy-on-write would have provided parallelism for free.
Instead, CPU progress (and arguably Moore's law itself) ended around 2007 with the arrival of the iPhone and Android, which sent R&D money to low-cost and low-power embedded chips. So the world was forced to jump on the GPU bandwagon, doubling down endlessly on SIMD instead of giving us MIMD.
Leaving us with what we have today: a dumpster fire of incompatible paradigms like OpenGL, Direct3D, Vulkan, Metal, TPUs, etc.
When we could have had transputers with unlimited compute and memory, scaling linearly with cost, that could run 3D and AI libraries as abstraction layers. Sadly that's only available in cloud computing currently.
We just got lucky that neural nets can run on GPUs. It would have been better to have access to the dozen or so other machine learning algorithms, especially genetic algorithms (which run poorly on GPUs).
forkrun's NUMA approach is really largely based on the idea that, as you said, "real workloads mostly wait for memory". The waiting for memory gets worse in NUMA because accessing memory from a different chiplet or a different socket requires accessing data that is physically farther from the CPU and thus has higher latency. forkrun takes a somewhat unique approach in dealing with this: instead of taking data in, putting it somewhere, and reshuffling it around based on demand, forkrun immediately puts it on the correct numa node's memory when it comes in. This creates a NUMA-striped global data memfd. on NUMA forkrun duplicates most of its machinery (indexer+scanner+worker pool) per node, and each node's machinery is only offered chunks from the global data memfd that are already on node-local memory.
This directly aims to solve (or at least reduce the effect from) "CPUs waiting for memory" on NUMA systems, where the wait (if memory has to cross sockets) can be substantial.
I don't know why you or your parent commenter got downvoted, but I use that as evidence that the end is very near.
With the current geopolitical climate and the arrival of AI, I'm predicting a sharp economic downturn at the end of the year the likes of which we haven't seen in a century.
I mean the Housing Bubble popping and the Dot Bomb were bad, but the US national debt was so much lower then. Income inequality was lower. Student loan debt was lower. Healthcare was more affordable. Homes were more affordable. Food was more affordable. We had (some) faith in our electoral process.
When the cheap capital runs out, when value of the dollar collapses due to unforced error, when the overseas investment dries up, when billionaires panic and yank their investment in AI (leaving us with a duopoly like always), when the employment rate peaks never to return, when companies stop hiring for the foreseeable future, when people stop visiting websites or buying software, when we abandon liberal arts for the trades in Service Economy 2.0, when hospitals and universities close, when farms go bankrupt, when interest on the US national debt consumes its social safety net, when we sell our public lands for pennies on the dollar, when nobody is held accountable..
That's when we the people will remember who we are. Somehow, like every other time before, we'll pull ourselves up by our bootstraps from nothing. Without time, money or resources, we'll come together and find a way to rebuild. We won't even tax the rich or incite violence against them, we'll simply manifest the abundant reality that's been denied to us by them for so long.
That looks like organizing. Unions. Cooperatives. Mutual aid networks. Renewable energy. Permaculture. Voluntary employment and clock-in. Credit unions and crowdfunding. Automation. Distributed means of production. Fair trade. Class action lawsuits. Boycotts. Voting against incumbents. Solarpunk.
We'll transcend competition and see the matrix for the bill of goods that it is. Rather than trying to get the money and power back in futility, we'll make them irrelevant.
It's time to start thinking about selling those stocks. Divesting from the blood money of unearned income that comes from exploitation, suffering and war (even though they don't tell us that). Steering clear of prediction markets. Dropping the crypto.
We know they won't. But that's why they'll stay insulated from knowing what stuff they're made of, holding out as long as possible, lonely and alone. And the fun part is, they'll get to find out anyway when the music stops.
{kind=link}
{kind=link}
{kind=link}
https://liucs.net/cs101s13/fixity.html
Anyway, it had several fatal flaws. I don't think it could handle images natively, so instead it encoded them as vectors and those files took up MB. It probably just needed a metaphor like iframe.
I remember when Apple switched to the PDF engine in Quartz in preparation for OS X in the late 90s, I thought it was a mistake then. The QuickDraw it was replacing was actually quite good, in some ways the epitome of C-style rendering. And Cocoa was refreshing at first (it handled stuff like palettes and gamma in a data-driven way instead of through leaky abstractions) but without a way to transition off QuickDraw, it felt like more busywork that had to be done just to keep up.
https://eclecticlight.co/2024/06/01/pdf-on-macs-the-rise-and...
Apple seems to have lost its academic roots, and suffers for it now. Or I should say, its customers suffer while it grosses almost half a trillion dollars per year. At least with vibe coding we can just whip up a Preview app in an afternoon, so maybe none of this matters anymore.
reply